
10 years ago, the DanBred breeding program was the first in the world to implement genomic selection for pigs, and today, genomic information is widely used for selection in most global-reaching pig breeding programs. Since its introduction, genomic selection has revolutionized pig breeding, as it ensures higher genetic gain at the same rate of inbreeding. The specific methods and technologies have undergone comprehensive developments throughout the years, and new breeding technologies are developing to increase long-term genetic gain.
By Tage Ostersen, Department Manager, and Lizette Vestergaard Pedersen, Consultant, Danish Pig Research Centre.
Increased genetic gain
Genomic information has revolutionized the pig breeding industry because it contributes to a more accurate prediction of breeding values, which in turn contributes directly to a higher genetic gain. As such, it has been instrumental for the high genetic gain we are continuously achieving. In the DanBred breeding program, we estimate that genomic selection increases genetic gain by 30 %, when all pigs are genotyped. These genetic improvements are cumulative and result in increased profits for pig producers each year.
The concept of genomic selection was first introduced in 2001 by Professor Theo Meuwissen and was implemented in the livestock industry relatively quickly. The basic principle in pig breeding remains the same. Pedigree and performance data are still essential, but genomic information provides an additional and more accurate source of information that can be utilized when calculating breeding values.
More accurate prediction of breeding values
The breeding value of a pig expresses the expected effect on the average performance (or phenotype) of its offspring. To calculate the breeding value before a pig has any offspring, we use advanced statistical mixed models that combine performance with relationship information. This elucidates which part of the performance expresses a pig’s genetic level and which part is simply random.
Before genomic selection was implemented, the relationships used in the statistical models were based on traditional pedigree. Pedigree relationships assume that two full sibs are always 50 % related. However, we know that the assumption of 50 % relatedness for full sibs is not entirely exact, it is just an average. It is a fact that each parent passes on half of its genes, but in one extreme scenario it is possible that two full sibs could receive the exact same half from their parents, meaning that they would be 100 % related. In the opposite extreme scenario, it is possible that two full sibs could receive the exact opposite halves from their parents, meaning that they would be 0 % related (i.e. unrelated).

Figure 1. The figure illustrates a simplified example of the fact that sibs can be more or less related genetically. The sow and the boar have their own individual DNA sets, and each pass on exactly half of their set to the offspring. But precisely which half is passed on to each piglet is random. In this example, piglet 1 has inherited a blue DNA-part from the boar and an orange DNA-part from the sow, whereas piglet 2 has inherited a green DNA-part from the boar and a red DNA-part from the sow. Evidently, both piglet 1 and 2 have inherited half of the genes from the boar and sow, but the parts are completely different. Consequently, piglets 1 and 2 are 0 % related to each other. The last offspring, piglet 3, has inherited half of each coloured DNA-part from the sow and boar, and is therefore 50 % related to piglet 1 and piglet 2.
With genomic information, we can measure the relatedness based on similarity at the genetic level, because we use thousands of markers across the genome to achieve this more precise measure of genomic relatedness. This is then utilized in our statistical models to distinguish the genetic part of the phenotype from the non-genetic part – i.e. to calculate more exact breeding values.
|
The Breeders Equation More accurate predictions of breeding values contribute directly to a higher genetic gain. The Breeders Equation explains how different changes in the breeding scheme will affect genetic gain (∆G): ∆G= (r ∙i ∙s)/L r is the accuracy of breeding values, i is the intensity of selection, s is the genetic standard deviation, and L is the generation interval. Genomic selection increases the accuracy and, thereby, contributes to an increased genetic gain. |
Improving challenging traits
Genomic selection increases genetic gain for all traits included in the breeding goal, but especially challenging traits such as feed conversion and litter size benefit. Feed conversion is very costly to measure, and only some of the pigs are performance tested (phenotyped). Litter size is a lowly heritable trait measured after the pigs are selected for breeding.
With genomic selection, however, additional information is used to estimate more accurate breeding values at an earlier point, thus leading to higher genetic gains – especially for these challenging traits, which would have otherwise been costly or slow to progress at the same level as achieved by using genomic selection.
The evolution of genomic selection
In the beginning, the cost of genotyping was high, resulting in a low proportion of genotyped pigs. In fact, the cost was 10-15 times higher in 2010 than it is today, and this expense was not offset by matching genetic gain for the most economically important traits. Consequently, advanced genotyping strategies were therefore developed in order to save costs. These genotyping strategies sought to maximize genetic gain through a balance of genotyping pigs that showed promise for breeding and pigs that could improve the prediction of other pigs – i.e. become “reference pigs”. We, therefore, partly genotyped the best-performing pigs, and partly genotyped pigs with abundant performance test information.
Today, the price of genotyping has decreased to a level where all global-reaching breeding programs genotype the majority of their breeding candidates, which has reduced the need to develop genotyping strategies. The genotyping process itself has also been developed and improved to the point, where the benefits in terms of genetic gain justify the inclusion of this extra step and cost. DanBred began to genotype 10 % of all selection candidates as early as in 2010, and since 2017, DanBred has genotyped 100 % of selection candidates. That is more than 100.000 pigs each year.
Cutting-edge computing power
The DanBred breeding program was the first to utilize genomic selection in pigs. As a result, Danbred were often the first to face new challenges, including those associated with the exponential growth in the number of genotyped pigs. During the first 10 years of genomic selection, the total number of genotyped pigs doubled approximately every second year. This led to considerable computational challenges. With standard genomic selection methods, doubling the number of genotyped pigs increases the computational load by a factor of between four and eight. The computational load has, therefore, increased several hundred times since DanBred began using genomic selection.
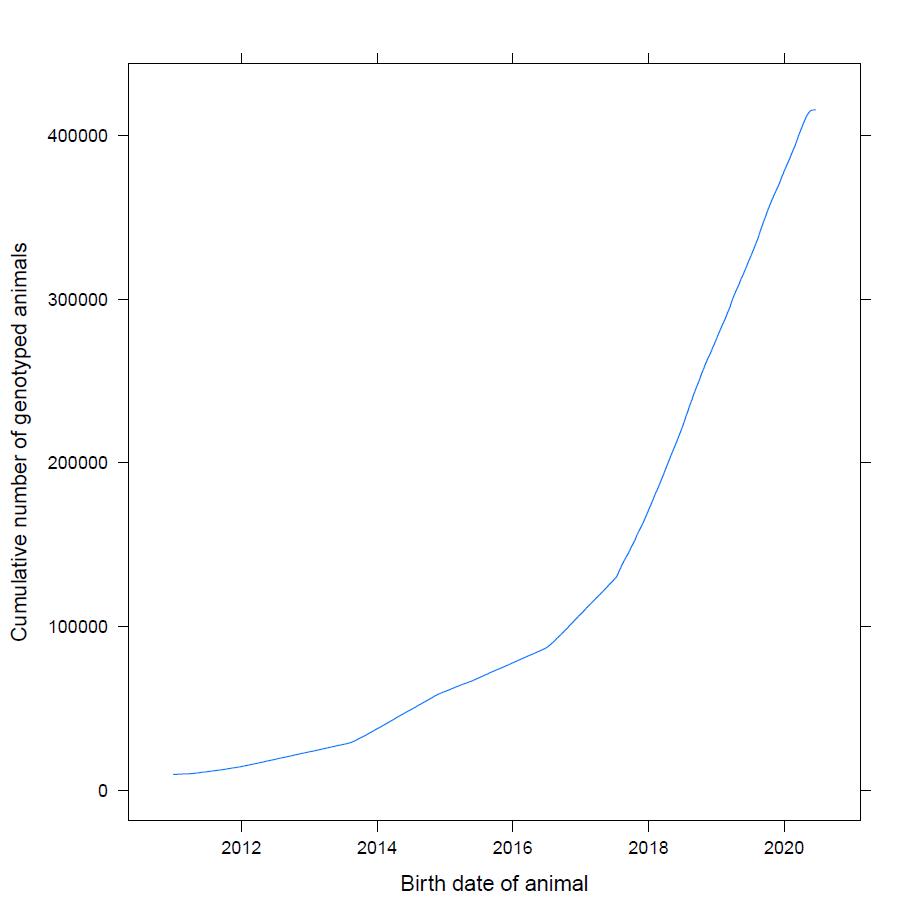
Figure 2. The graph shows the cumulative number of genotyped DanBred pigs over the years. Since 2017, DanBred has genotyped 100 % of all selection candidates.
To accommodate these challenges, DanBred has repeatedly doubled the computing power and implemented new methods to reduce the computational load. Most recently, DanBred has implemented the solver facilities from the Linear Models Toolbox (LMT), which is a generalized linear mixed model software frame developed and maintained by the Centre for Quantitative Genetics and Genomics (QGG) at Aarhus University, as a successor to its popular DMU package. In that regard, we are the first breeding company to replace DMU by LMT, and this has enabled DanBred to decrease the processing time by about 90 %.
Metabolomics as the next leap for pig breeding
Genomic selection has substantially enhanced the breeder’s toolbox, contributing with increased long-term genetic gain. Genomic selection is still developing, and other interesting breeding tools are also beginning to emerge. For instance, metabolomic selection which is a breeding technology that uses nuclear magnetic resonance data (or NMR).
NMR metabolomics measures all the metabolites in a sample from an individual. This complete set of metabolites – referred to as whole-metabolomic data – is associated with the level of physiological activity in biological pathways that are initiated at a DNA level and culminate in trait expression (performance). The level of physiological activity is, in turn, regulated by the genes that an individual has inherited from its parents, as well as by influence from its environment. This link between whole-metabolomic data and inherited genes may be exploited to increase the genetic potential for desirable traits such as feed efficiency in pigs.
To explore this potential next leap for pig breeding, DanBred, the Danish Pig Research Centre, Nordic Seed, and Aarhus University have partnered on a new a R&D metabolomics project, where whole-metabolomic data in combination with phenotypic, pedigree, and genomic data will be used to further investigate feed efficiency and meat quality traits, etc. Subsequently, the experts will conduct metabolomic analysis, develop statistical models, and plan the implementation of the findings into the DanBred breeding programme. The project is partially funded with ~ €1.1 million from the Green Development and Demonstration Programme under the Ministry of Environment and Food in Denmark.
This is an example of how partnerships of many expert actors are already busy taking the next great leap for pig genetics, thus driving the development of the industry towards a more efficient and sustainable global pig production.








